

APRIL FOOLS PROTOTYPE

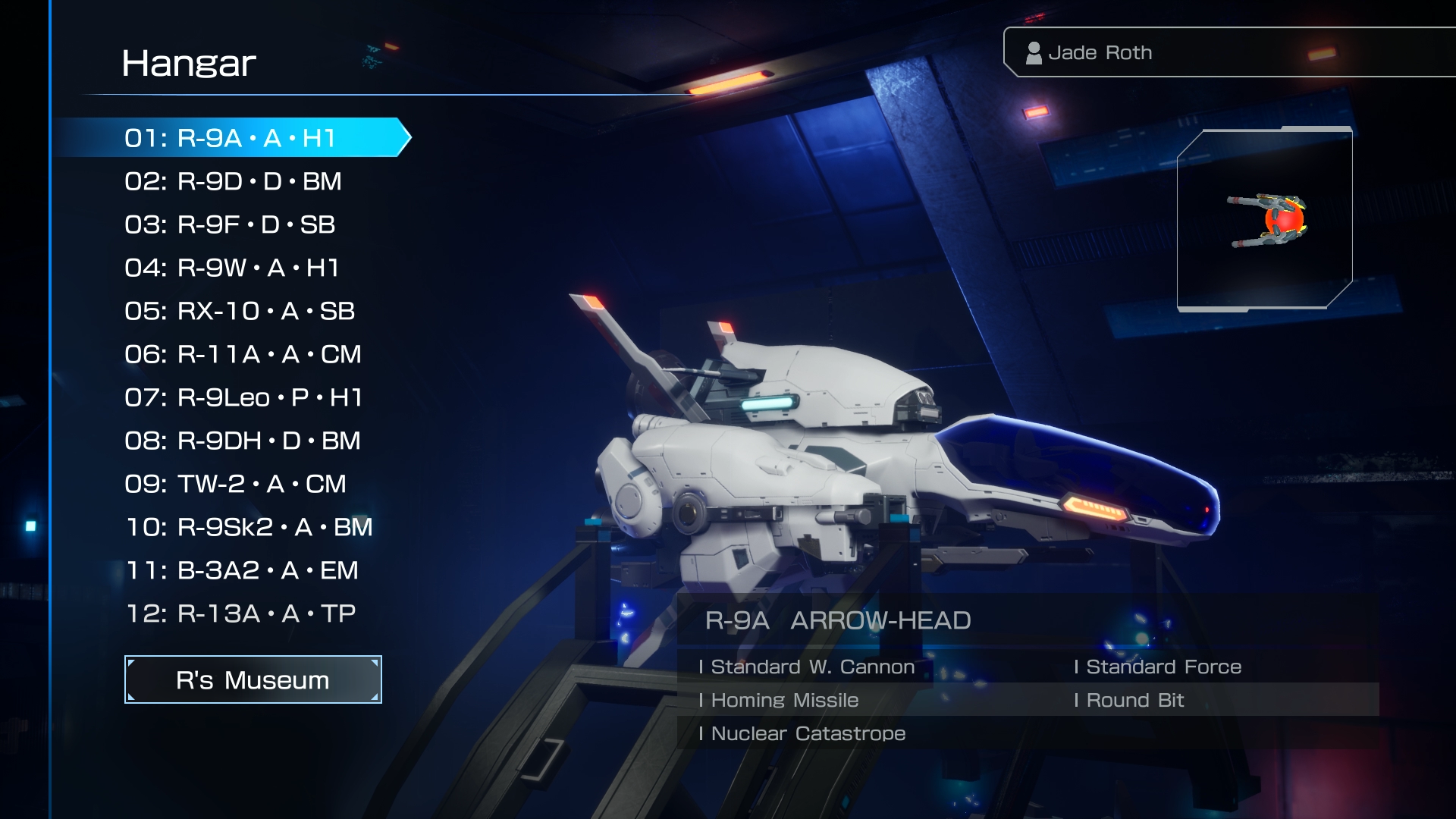
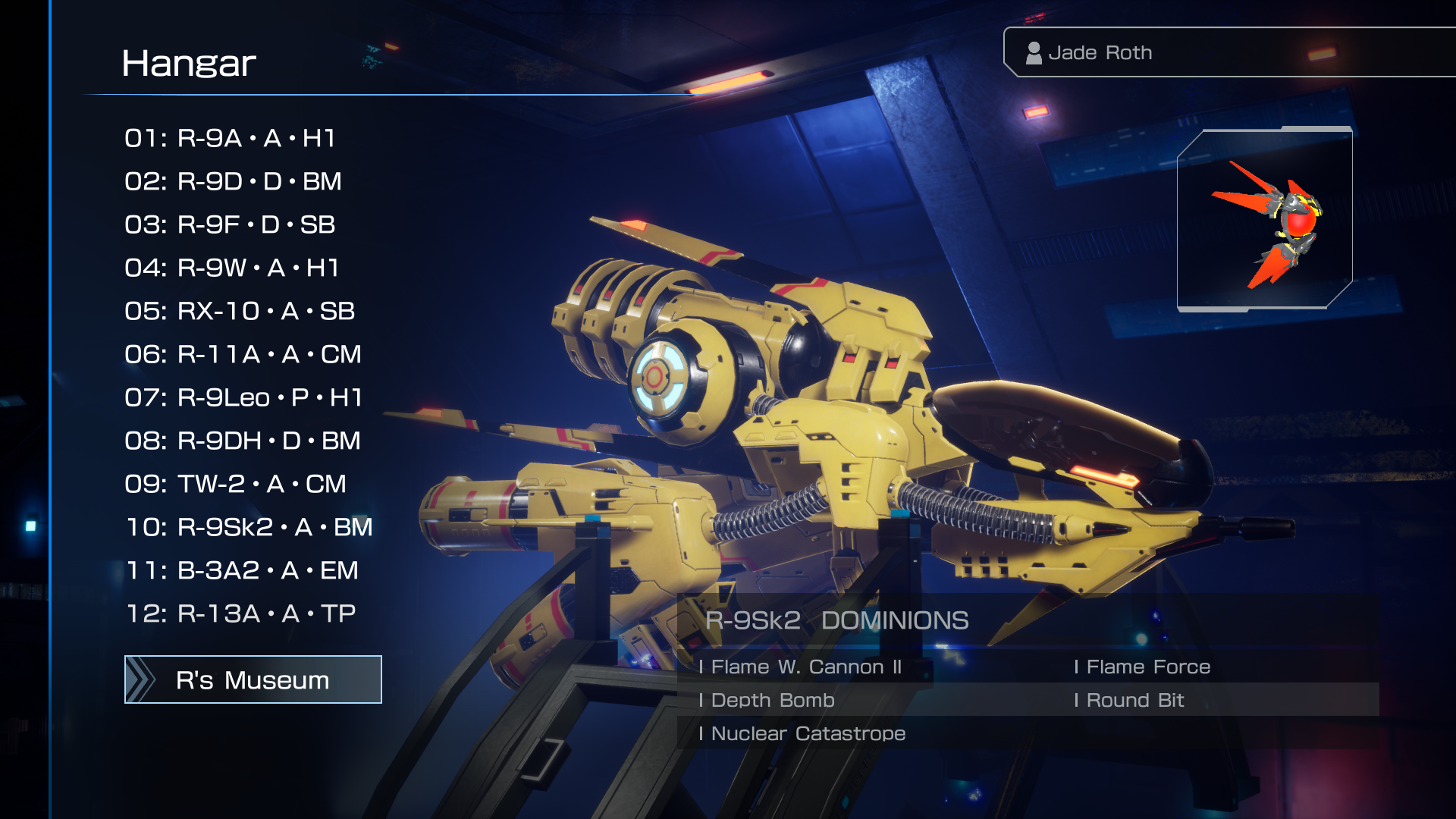
Includes a new ship.
”`scala val numbers = Array(1, 2, 3, 4, 5) val doubledNumbers = numbers.map(x => x * 2) // doubledNumbers: Array[Int] = Array(2, 4, 6, 8, 10)
Unlike traditional data processing systems, Apache Spark is designed to handle large-scale data processing with high performance and efficiency. Scala is a multi-paradigm programming language that runs on the Java Virtual Machine (JVM). It’s used in Apache Spark because of its concise and expressive syntax, which makes it ideal for big data processing.
RDDs are created by loading data from external storage systems, such as HDFS, or by transforming existing RDDs.
Includes a new ship.









”`scala val numbers = Array(1, 2, 3, 4, 5) val doubledNumbers = numbers.map(x => x * 2) // doubledNumbers: Array[Int] = Array(2, 4, 6, 8, 10)
Unlike traditional data processing systems, Apache Spark is designed to handle large-scale data processing with high performance and efficiency. Scala is a multi-paradigm programming language that runs on the Java Virtual Machine (JVM). It’s used in Apache Spark because of its concise and expressive syntax, which makes it ideal for big data processing. Apache Spark Scala Interview Questions- Shyam Mallesh
RDDs are created by loading data from external storage systems, such as HDFS, or by transforming existing RDDs. ”`scala val numbers = Array(1, 2, 3, 4,